Code
AI
Design
Do handoff ao código em alta velocidade

Esse post é sobre um experimento real. Não é um tutorial de IA, não é promessa de "10x developer". É o relato honesto de como analisamos nosso processo de entrega, identificamos onde estava consumindo tempo(de forma improdutiva) e testamos formas de acelerar sem abrir mão de qualidade.
O contexto: estávamos em um projeto para um cliente que vende planos de assistência médica: um produto com backoffice, onboarding, app. E a Novatics, inserida num cenário onde a Inteligência Artificial deixou de ser apenas um recurso extra para se tornar base das operações tecnológicas, buscou compreender as melhores estratégias e pontos de integração para incorporar essa inteligência nos fluxos de trabalho. Foi justamente esse momento que nos forçou a olhar pro nosso processo. Esse olhar abriu uma porta: entender onde a IA poderia entrar não como solução mágica, mas como alavanca para melhorar o que já existia e liberar o time para usar o tempo com o que realmente importa: pensar em solução de produto.
Aqui, design e desenvolvimento sempre trabalharam próximos, co-criação, alinhamento contínuo, processo colaborativo. Não é uma empresa onde o designer joga o arquivo para o desenvolvedor e some. Mesmo assim, a gente percebia que a implementação frequentemente não correspondia ao que havia sido entregue. Espaçamentos ligeiramente diferentes, tokens não respeitados, componentes recriados do zero quando já existiam na biblioteca. Nada catastrófico isoladamente, mas acumulado, isso virava retrabalho, ida e volta, e tempo que poderia estar sendo usado em outra coisa. Quando a gente parou pra olhar pra esse padrão com atenção, foi claro: aqui tem um problema.
Antes de acelerar, a gente precisava entender onde estava travando
A primeira coisa que fizemos não foi instalar nenhuma ferramenta nova. Foi sentar e olhar pro que estava acontecendo.
Um problema central era o Shadcn. A gente já usava Shadcn como fundação de componentes em projetos anteriores, mas a implementação no Figma era inconsistente: os componentes que existiam na biblioteca não correspondiam ao que a biblioteca de código realmente entregava. O resultado era previsível: o dev abria o Figma, via que o componente não batia com o Shadcn, e precisava voltar pro designer pra tirar dúvida. O designer precisava ir no código para entender o que estava disponível. Idas e vindas que ninguém planeja, mas que todo mundo vive.
Daí três problemas concretos apareceram nessa análise:
Componentes incompletos ou inconsistentes com a biblioteca real. Fazer componentes do zero tem um custo alto, afinal leva tempo. Alterações feitas de forma ad hoc num projeto não eram replicadas para outros projetos. E validações técnicas recorrentes viravam rotina: não porque o time era desorganizado, mas porque não havia uma fonte de verdade.
Escalar variações visuais dá trabalho de verdade. Usar Shadcn como fundação ajuda muito na velocidade de entrega. Mas quando você começa a criar variações de tema, estados de componente, teste com componentes agrupados para entender o comportamento em conjunto consomem um tempo que são subestimados, muitas vezes.
Atualização manual de tokens no Figma é operacionalmente cara. Depois que os tokens de cor, tipografia e border radius são definidos, alguém precisa ir lá no arquivo e atualizar tudo a mão. É um trabalho que não tem retorno criativo nenhum, mas que se feito errado quebra a consistência do projeto inteiro.
O que nós fizemos na prática
1. Encontrar um arquivo Figma que fosse fiel à biblioteca
O primeiro passo foi buscar um arquivo base do Shadcn no Figma que fosse o mais próximo possível do que a biblioteca de código realmente entrega. Parece óbvio, mas não é, existem vários arquivos circulando na comunidade que estão desatualizados ou que interpretam os componentes de forma livre demais.
A referência que usamos é próprio ui.shadcn.com como guia. Dentro do site ele recomenda vários arquivos (https://ui.shadcn.com/docs/figma). Escolhemos o Obra shadcn/ui Pro by Obra Studio. Estudamos as estrutura dos componentes, o arquivo, e fizemos um de-para do arquivo com o que o site mostra. Ficou de lição: entender os tokens nós dá um conhecimento das possibilidades, além de ver aplicações de componentes específicos, e isso tem conexão direta com o quão rápido você atualiza o arquivo para uma nova identidade visual.
Outra coisa aprendemos foi: tokens de cores não precisam ser Tailwind. Apesar dos devs sempre levantarem que era um pré-requisito e muita gente utilizá-los. Eles precisam ser coerentes com o que o código vai consumir, não é questão de ser Tailwind puro.
Outra percepção importante que veio desse processo: o Figma é limitado. Ele não consegue representar 100% dos estados e comportamentos que a biblioteca entrega. Isso não é crítica ao Figma: é só uma realidade que o time precisa ter alinhada. O arquivo de design é uma aproximação, não um espelho perfeito do código.
Um exemplo concreto: alguns botões precisam de background para aplicar o focus ring, que no Figma é colocado como Effects: porque o botão já tem um Stroke, e para o Effect funcionar é necessário um Fill. Por isso existe o unofficial fill, que na implementação em código não existe, mas no Figma é necessário para que o estado de Focus funcione visualmente. São os tipos de decisão que precisam estar documentadas para não virar dúvida recorrente.

2. Validar os temas antes de comprometer o arquivo
Antes de ir diretamente no Figma para visualizar cores e aplicações, passamos a usar o Tweakcn pra testar variações de tema de forma rápida. Você mexe nas cores, tipografia, border radius e já vê como os componentes se comportam juntos: sem precisar comprometer muito o seu tempo replicando componentes e fazendo na mão. A interface é fácil de mexer e dá pra entender instantaneamente qual token tem impacto em qual componente.

Tema original
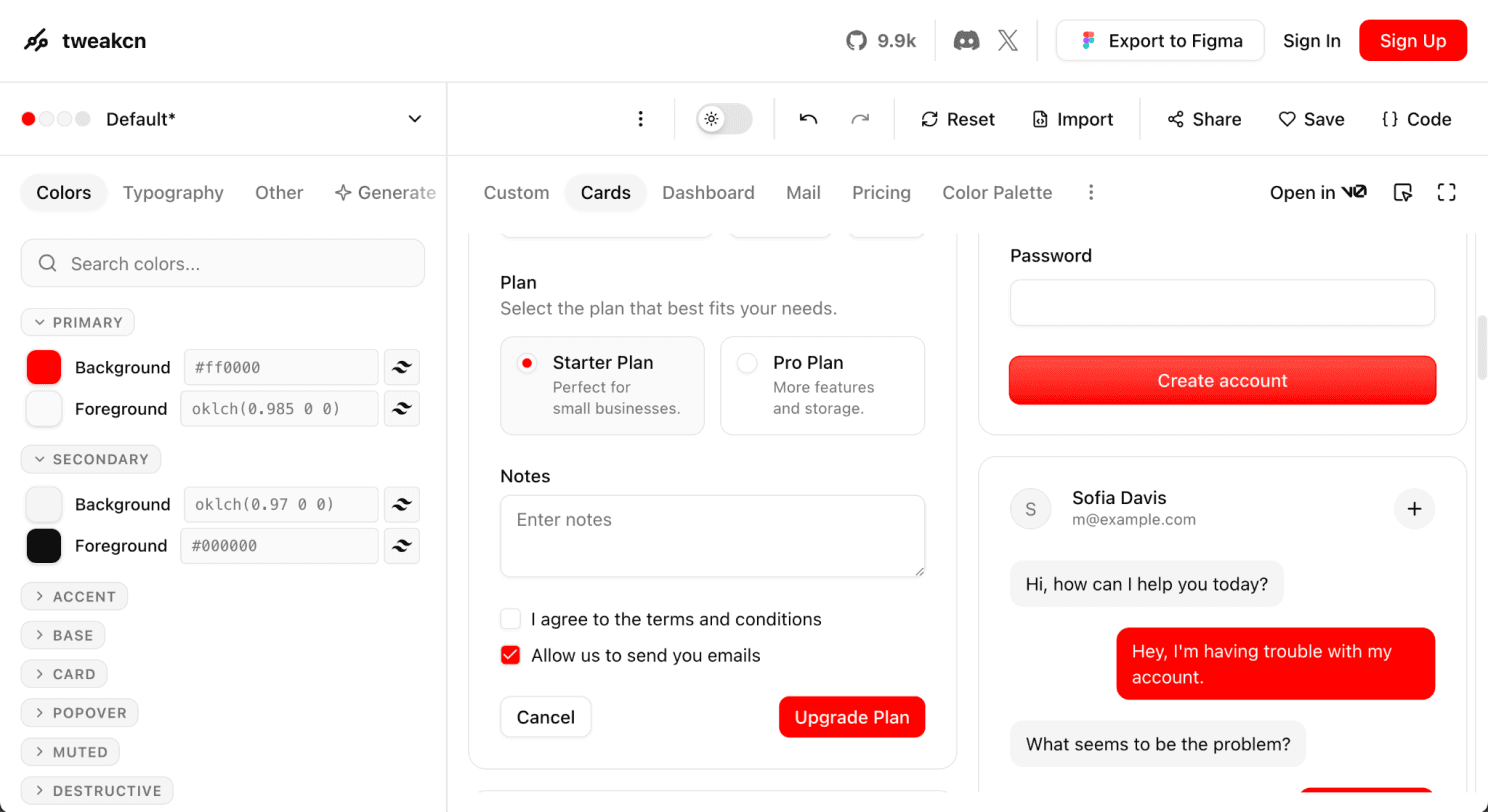
Tema personalizado para marca de um cliente/empresa
Conseguimos entender aqui, onde a mudança da cor do background vermelho atinge: o fundo da check box, do radio button, o botão principal e o background das mensagens.
Por exemplo: mudando a cor primary para vermelho, é possível visualizar de uma vez que isso afeta o fundo do checkbox, o radio button, o botão principal e o background das mensagens. Com isso, se eu quiser que o fundo do checkbox seja diferente da cor do botão principal, como foi o caso nesse projeto, preciso criar um novo token de cor. Isso não tem grande impacto no desenvolvimento, mas é necessário apontar pros devs que houve essa mudança. No nosso caso chamamos esses tokens de unofficial, pra ficar claro na coleção de organização de cores.

Visão das variáveis do Figma
Fazer uso do Tweakcn mudou o fluxo de validação. Em vez de testar paletas, aplicar no Figma, visualizar, testar e depois propor para o time: nós identificamos inconsistências muito antes, e conseguimos até validar com o cliente mais rápido. O custo de erro caiu.
3. Atualizar a biblioteca no arquivo final de forma incremental e organizada
A atualização dos tokens e componentes no Figma foi feita de forma incremental, com priorização orientada pelo escopo do projeto. Não tem sentido atualizar todos os 40 componentes da biblioteca antes de começar a desenhar. Começamos por aqueles que eram necessários segundo o cronograma do projeto, nesse caso: botões, labels, inputs.
Para a atualização em si, alguns plugins do Figma ajudaram muito:
Similayer: seleção rápida de elementos semelhantes para edição em lote
Obra Shadcn/UI Tools: para "desproperizar" componentes e editar vários documentos de uma vez
Propstar: organização de variáveis
Batch Styler: mudança de tipografia em lote
Combinados eles eliminam o trabalho mecânico que consome atenção sem gerar valor.
4. Um arquivo organizado protege o dev de implementar o que ainda não está pronto
Esse ponto parece simples, mas tem um impacto real no dia a dia. Reforçando o que foi dito antes, quando o arquivo usa convenções claras de status o dev sabe exatamente o que pode implementar sem risco de retrabalho.
Sem isso, o que acontece? O dev pega uma tela que parece pronta, implementa, e dois dias depois o designer atualiza o componente. Retrabalho desnecessário dos dois lados.
Organizamos da seguinte forma: um arquivo para Biblioteca de componentes e outro para Handoff de produto.
Dentro do arquivo de Handoff existe uma clara separação entre exploração, telas finais (que chamamos de handoff) e protótipos. E a depender da complexidade do projeto (se for grande), a exploração fica num terceiro arquivo, deixando ainda mais enxuto o handoff, diminuindo possibilidade de erro.

No arquivo de componentes, o sistema de indicadores transformou o arquivo num contrato visual entre design e desenvolvimento.
🟡 Atualização em progresso
✓ Atualização finalizada
⊕ Componente novo adicionado à biblioteca
Parece detalhe, mas faz diferença enorme no alinhamento interno. Qualquer pessoa que abre o arquivo sabe exatamente o que está consolidado e o que ainda está em movimento.
A regra prática: dev só implementa o que tem ✓ e o que está em Handoff. O resto ainda está em movimento.
5. O arquivo de solução é derivado da biblioteca, não o contrário
Essa parece uma decisão óbvia, mas ela precisa ser explícita: o arquivo de solução (onde ficam os handoffs de tela) é o espelho do produto. A biblioteca é a fonte de verdade dos componentes. O arquivo de solução consome a biblioteca, ele não cria componentes por conta própria.
Quando essa separação está clara, a construção dos handoffs fica muito mais rápida. O designer monta a tela usando componentes já validados, já com os tokens certos, já com os estados mapeados. O que sobra pro handoff é mostrar a lógica de negócio, os fluxos, e as exceções e não explicar como um botão funciona.
Uma prática que também entrou no handoff: apontar explicitamente quais componentes do Shadcn estão sendo usados em cada tela. O dev não precisa inferir. Ele vê "esse card é o Card do Shadcn, essa tabela é o DataTable, esse dropdown é o Select", e já sabe por onde começar.


6. Adicionar MCP do Figma no processo (e organizar o arquivo pensando em como o MCP vai lê-lo)
O momento em que implementamos a IA: usar o MCP do Figma para intermediar biblioteca de componentes. O MCP (Model Context Protocol) não é apenas mais uma ferramenta: é o ponto de conexão que permite a modelos de IA acessarem o Figma de forma semântica. Através dele, a IA deixa de apenas "olhar" para uma imagem e passa a compreender a estrutura real de frames, variantes e design tokens. Diferente de plugins convencionais que executam tarefas isoladas, o MCP estabelece uma camada de contexto contínuo, transformando o design system em uma fonte de verdade automatizável. Na prática, isso significa que processos pesados de documentação e handoff deixam de consumir semanas para serem resolvidos em dias, eliminando o trabalho braçal e liberando o time para o que realmente importa.
Assim, uma boa parte do trabalho manual de customizar componentes e aplicar a base do design system no código passou a ser feito pela IA utilizando o Figma MCP. Isso acelera consideravelmente o fluxo de criação dos componentes e da UI do sistema em geral. Basicamente, os devs apontam o agente de IA para o frame correto do Figma e, com base em um prompt bem estruturado, o agente usa o MCP para implementar cada componente e suas variações.
Para esse processo funcionar corretamente, é fundamental organizar o arquivo pensando em como o MCP vai lê-lo. Quando você sabe que um agente de IA vai consumir o seu arquivo do Figma , não só um humano, a forma como você organiza as camadas começa a importar de um jeito diferente.

Botões implementados
Algumas boas práticas que adotamos:
Usar componentes da biblioteca, não cópias soltas. Quando o agente encontra uma instância de componente real, ele consegue associar ao código correspondente. Quando encontra um grupo de retângulos que "parece" um botão, ele precisa inferir: e inferência gera inconsistência.
Manter a hierarquia de camadas limpa. O get_design_context do FigmaMCP retorna a estrutura da camada selecionada. Se essa estrutura estiver aninhada de forma confusa, o contexto que chega pro agente é confuso também.
Separar bem os estados. Hover, focus, disabled: cada estado num frame próprio, nomeado corretamente. O agente precisa saber que existem variações, não só o estado default.

Botões no arquivo do Figma
Esse cuidado com a organização não é trabalho extra. É trabalho que você faria de qualquer forma para um dev humano, mas que agora também serve pra IA.
O que essa parte do processo ainda tem de manual (e tudo bem)
Seria desonesto terminar essa seção sem dizer: a atualização da biblioteca ainda é um trabalho operacional relevante. Os plugins ajudam, o processo organizado ajuda, mas alguém precisa sentar e fazer. Especialmente quando um projeto novo chega com uma identidade visual diferente, novas cores, nova tipografia, corner radius diferente, o esforço de adaptar a biblioteca é real.
O que mudou não foi eliminar esse trabalho. Foi torná-lo mais previsível, mais rápido de executar, e com menos retrabalho depois.
O que esse processo mostrou na prática é simples: velocidade não vem de atalhos, vem de clareza. Quando a biblioteca reflete o que o código entrega, quando o arquivo comunica o que está pronto ou não, e quando a IA entra num fluxo já organizado, o tempo que antes ia para retrabalho começa a ir para decisão de produto.
Como designer sênior, o papel nesse cenário muda um pouco: menos tempo explicando o óbvio para o dev, mais tempo garantindo que as decisões certas estejam documentadas antes de alguém implementar qualquer coisa. A IA não substitui esse julgamento, ela amplifica. E é justamente por isso que vale a pena investir na organização antes de acelerar.
Escrito por Marina Alves